續上一篇機器學習 挑戰 - Day 5,
我們今天繼續詳細研究一下如何套用 tensorflow.keras.sequential 來預測BTC的價格。
我想嘗試2種類型的模型。一個使用LSTM(model2),另一個不使用(model1)。
為什麼必須將訓練過程分配給一個變數呢?
原因是因為model.fit(...)返回一個包含訓練性能的對象。
在TensorFlow中,使用.fit(...)返回一個具有模型訓練性能的對象。這個對象可以用於可視化這些性能並詳細分析它們。
在model.compile中,我們選擇'mse',這意味著均方誤差,它取預測和實際輸出之間的差異,對其進行平方並在整個數據集上進行平均。
我們將使用"Adam"作為優化器,因為我發現"AdamW"已經無法使用。
Model 1: feedforward neural network (FNN)
模型1是使用前饋神經網絡(FNN)構建的,其中信息在其各層之間的流動是雙向的,這意味著模型中的信息僅以一個方向流動,即從輸入節點,通過隱藏節點(如果有的話)並到達輸出節點,沒有循環或迴圈。
我選擇100 epoch代表我要訓練數據集完整地通過算法100次。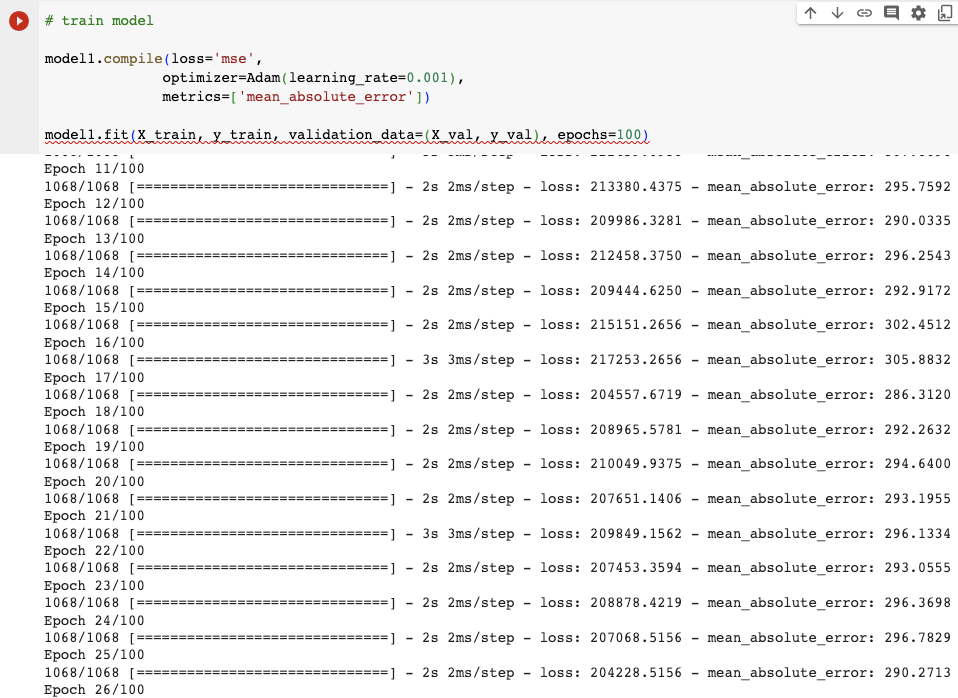
可以看到以上的mean_absolute_error數值在290跟300重複來回。到100次時也只降到了286。
把model訓練的成果用圖顯示的話,
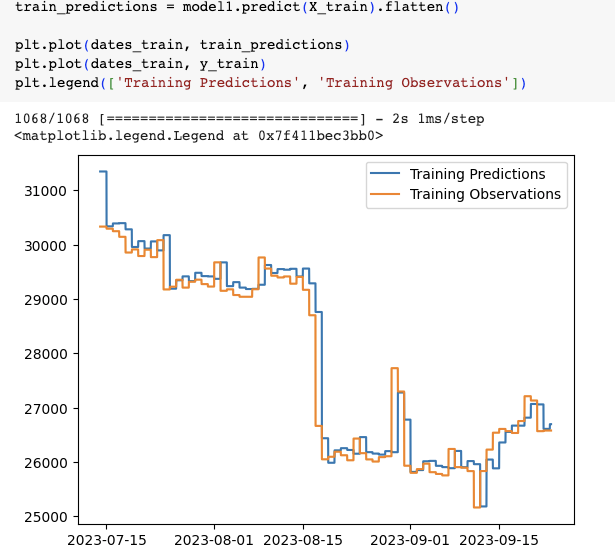
在training set中訓練的model看似蠻相近的,我們再看看validation以及testing。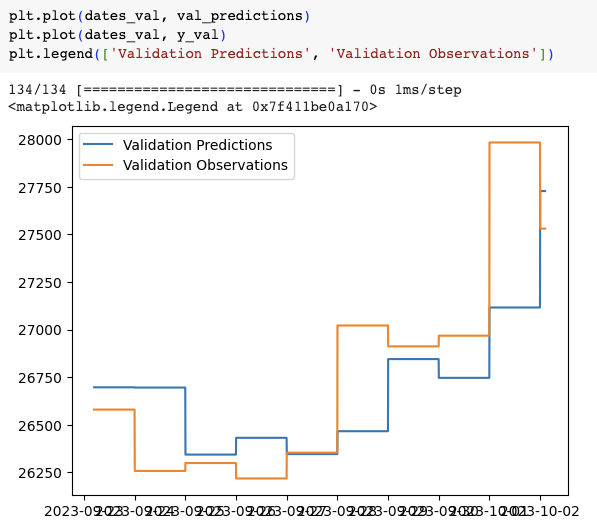
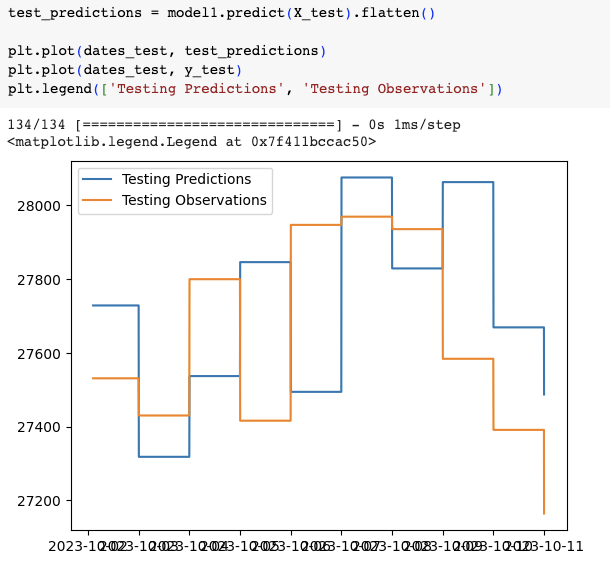
我們可以看出model1可預測的還是很不準確,有一些預測直接跟實際closing price正相反。
Model 2: Recurrent Neural Network with LSTM?
LSTM是RNN(循環神經網絡)的一種特殊類型,能夠學習長期依賴性。
套上一樣的訓練次數,我們看看model2的mse。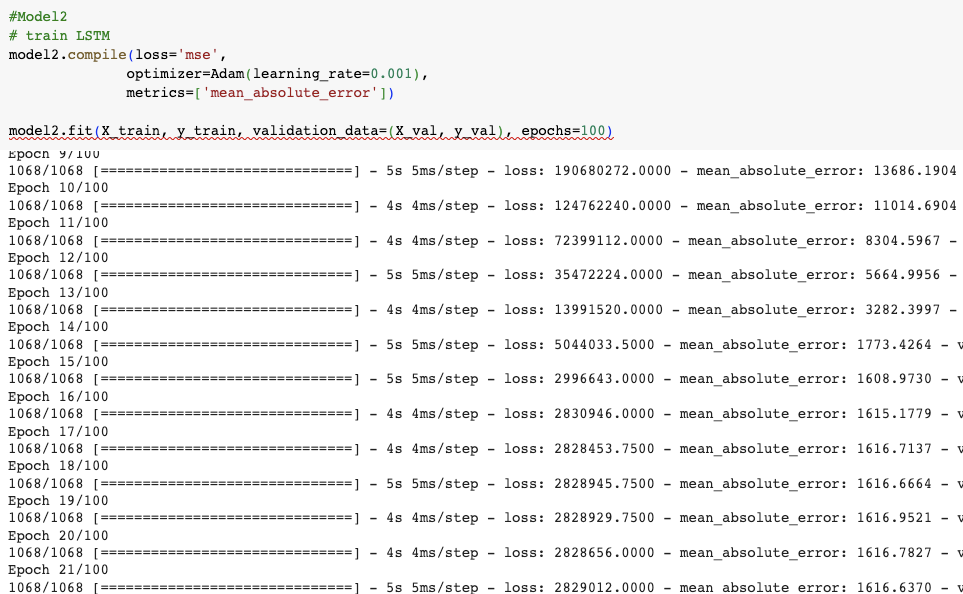
從上圖可以看出 model2的mse更高!最後一直在1600之間重複來回。
把model訓練的成果用圖顯示的話,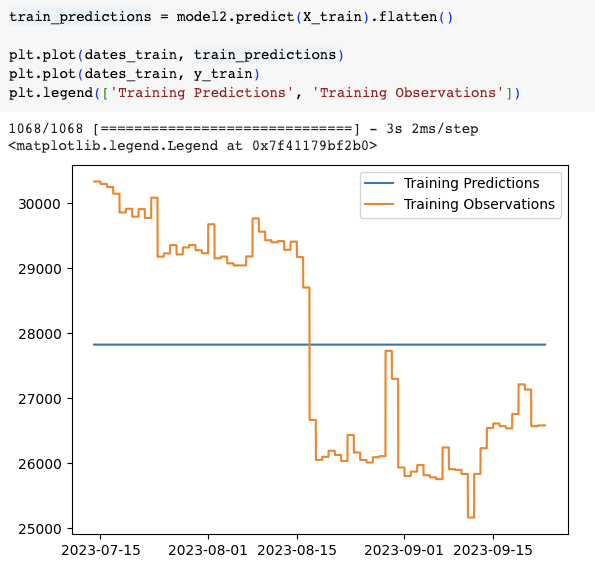
model2完全直接預測一條直線!
我們再看看validation以及testing。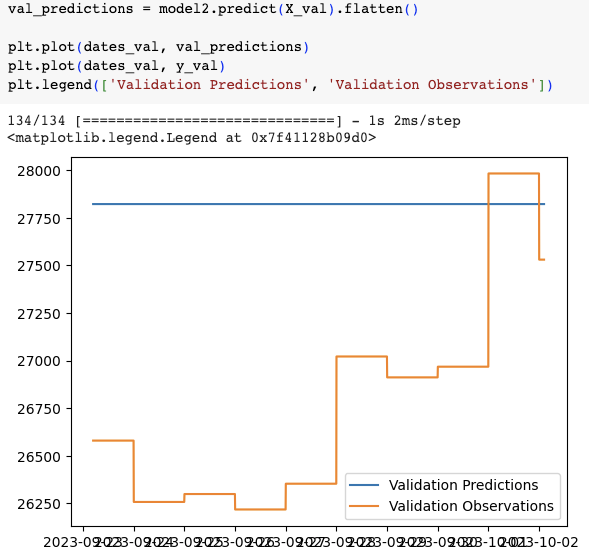
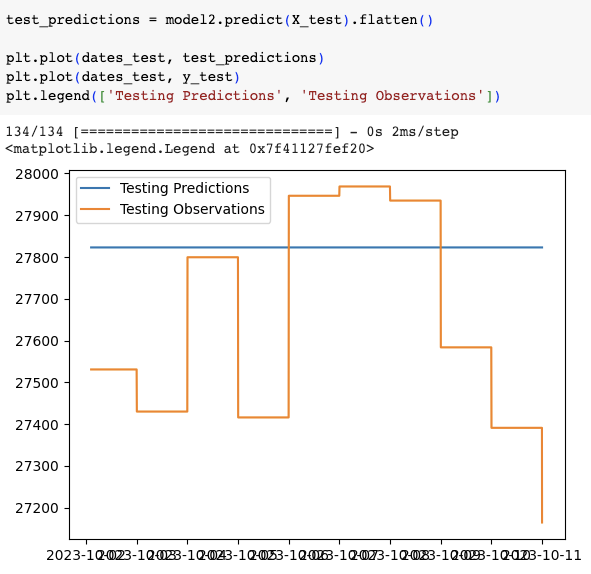
直線跟上兩圖的closing price最高點還蠻接近的,但期間的波動就完全沒預測到。
以下是一些主要區別:
層類型:
數據輸入形狀:
層激活函數:
架構和連接:
應用案例:
總之,model1 在這情況比較適合。
在下一篇,我想要研究一下可否加入多項其他變數來預測未來價格。
其他參考資料:
https://machinelearningmastery.com/rectified-linear-activation-function-for-deep-learning-neural-networks/
https://towardsdatascience.com/stochastic-gradient-descent-clearly-explained-53d239905d31
https://keras.io/api/layers/recurrent_layers/lstm/
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
對 dbt 或 data 有興趣?歡迎加入 dbt community 到 #local-taipei 找我們,也有實體 Meetup 請到 dbt Taipei Meetup 報名參加
Ref:
https://levelup.gitconnected.com/20-pandas-functions-for-80-of-your-data-science-tasks-b610c8bfe63c

